How to Handle Missing Data Values While Data Cleaning

One of the major challenges in most business intelligence (BI) projects is data quality (or lack thereof). In fact, most project teams spend 60 to 80 percent of total project time cleaning their data—and this goes for both BI and predictive analytics.
To improve the effectiveness of the data cleaning process, the current trend is to migrate from manual data cleaning to more intelligent, machine learning-based processes.
Identify the Missing Data Values
Most analytics projects will encounter three possible types of missing data values, depending on whether there’s a relationship between the missing data and the other data in the dataset:
- Missing completely at random (MCAR): In this case, there may be no pattern as to why a column’s data is missing. For example, survey data is missing because someone could not make it to an appointment, or an administrator misplaces the test results he is supposed to enter into the computer. The reason for the missing values is unrelated to the data in the dataset.
- Missing at random (MAR): In this scenario, the reason the data is missing in a column can be explained by the data in other columns. For example, a school student who scores above the cutoff is typically given a grade. So, a missing grade for a student can be explained by the column that has scores below the cutoff. The reason for these missing values can be described by data in another column.
- Missing not at random (MNAR): Sometimes, the missing value is related to the value itself. For example, higher income people may not disclose their incomes. Here, there is a correlation between the missing values and the actual income. The missing values are not dependent on other variables in the dataset.
How to Handle Missing Data Values
Data teams can use a number of strategies to handle missing data. On one hand, algorithms such as random forest and KNN are robust in dealing with missing values.
On the other hand, you may have to deal with missing data on your own. The first common strategy for dealing with missing data is to delete the rows with missing values. Typically, any row which has a missing value in any cell gets deleted. However, this often means many rows will get removed, leading to loss of information and data. Therefore, this method is typically not used when there are few data samples.
You can also impute the missing data. This can be based solely on information in the column that has missing values, or it can be based on other columns present in the dataset.
Finally, you can use classification or regression models to predict missing values.
Let’s look at these three strategies in depth:
1. Missing Values in Numerical Columns
The first approach is to replace the missing value with one of the following strategies:
- Replace it with a constant value. This can be a good approach when used in discussion with the domain expert for the data we are dealing with.
- Replace it with the mean or median. This is a decent approach when the data size is small—but it does add bias.
- Replace it with values by using information from other columns.
In the employee dataset subset below, we have salary data missing in three rows. We also have State and Years of Experience columns in the dataset:
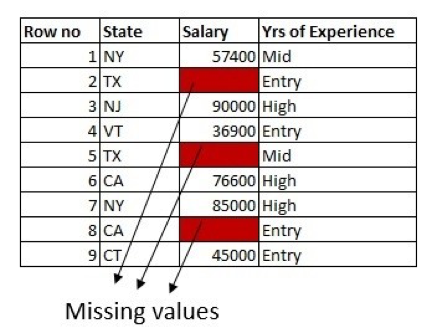
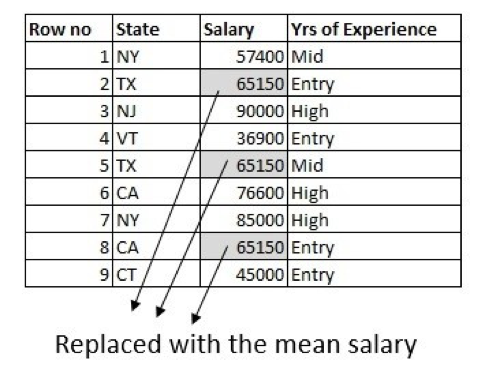
The first approach is to fill the missing values with the mean of the column. Here, we are solely using the information from the column which has missing values:
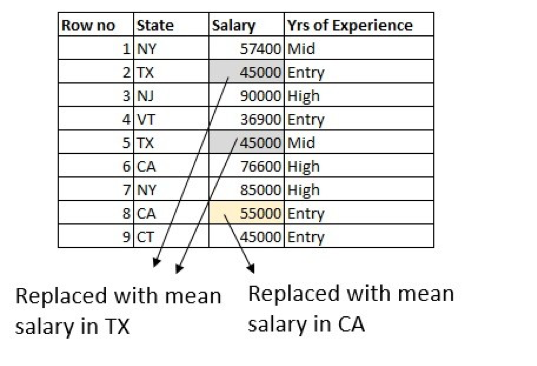
With the help of a domain expert, we can do little better by using information from other columns in the dataset. The average salary is different for different states, so we can use that to fill in the values. For example, calculate the average salary of people working in Texas and replace the missing data with an average salary of people who typically work in Texas:
What else can we do better? How about making use of the Years of Experience column as well? Calculate the average entry-level salary of people working in Texas and replace the row where the salary is missing for an entry-level person in Texas. Do the same for the mid-level and high-level salaries:
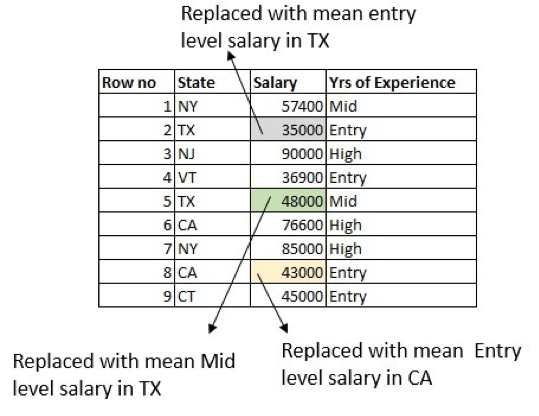
Note that there are some boundary conditions. For example, there might be a row that has missing values in both the Salary and Years of Experience columns. There are multiple ways to handle this, but the most straightforward is to replace the missing value with the average salary in Texas.
2. Predicting Missing Values Using an Algorithm
Another way to predict missing values is to create a simple regression model. The column to predict here is the Salary, using other columns in the dataset. If there are missing values in the input columns, we must handle those conditions when creating the predictive model. A simple way to manage this is to choose only the features that do not have missing values, or take the rows that do not have missing values in any of the cells.
3. Missing Values in Categorical Columns
Dealing with missing data values in categorical columns is a lot easier than in numerical columns. Simply replace the missing value with a constant value or the most popular category. This is a good approach when the data size small, though it does add bias.
For example, say we have a column for Education with two possible values: High School and College. If there are more people with a college degree in the dataset, we can replace the missing value with College Degree:
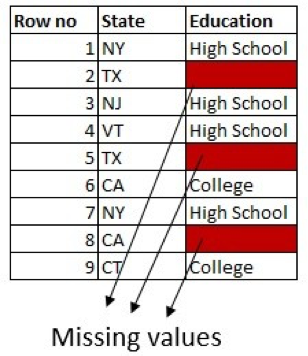
We can tweak this more by making use of information in the other columns. For example, if there are more people from Texas with High School in the dataset, replace the missing values in rows for people from Texas with High School.
One can also create a classification model. The column to predict here is Education, using other columns in the dataset. But the most common and popular approach is to model the missing value in a categorical column as a new category called Unknown:
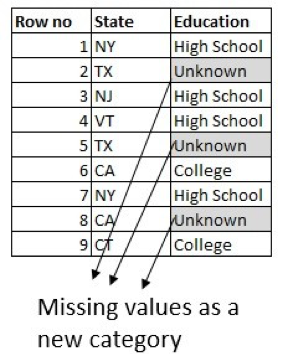
In summary, you’ll use different approaches to handle missing data values while data cleaning depending on the type of data and the problem at hand. If you have access to a domain expert, always incorporate their expert advice when filling in the missing values.
Most importantly, no matter the imputation method you choose, always run the predictive analytics model to see which one works best from the standpoint of data accuracy.

The Definitive Guide to Predictive Analytics
Download Now: